$ printf "Look, I have something inside" > /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
$ printf "\nNow I have one more thing" >> /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
Now I have one more thing
$
What really happens is:
$ printf "Look, I have something inside" > /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside$ printf "\nNow I have one more thing" >> /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
Now I have one more thing$
And what you want is:
$ printf "Look, I have something inside\n" > /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
$ printf "Now I have one more thing\n" >> /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
Now I have one more thing
$
Newlines are line terminators, not separators. This article missed what could have been a really good section on line buffering that could have explained some of the merit of having line terminators as opposed to line separators.
$ printf "Look, I have something inside" > /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside%
$ printf "\nNow I have one more thing" >> /tmp/careful.txt
$ cat /tmp/careful.txt
Look, I have something inside
Now I have one more thing%
$
Zsh will add the line break and mark its absence with a % with reverse video).
I follow the "terminator-not-separator" rule religiously in my own source code, but my impression is that this is somewhat a Unix-ism.
Which defines it this way, because various original Unix components (including things like stdio) will break in various surprising and inconsistent ways when text file does not end in \n or contains lines longer than some arbitrary limit (which is why POSIX has LINE_MAX).
It's very much in favour of consistency as well as simplicity and therefore predictability that newlines should be terminators.
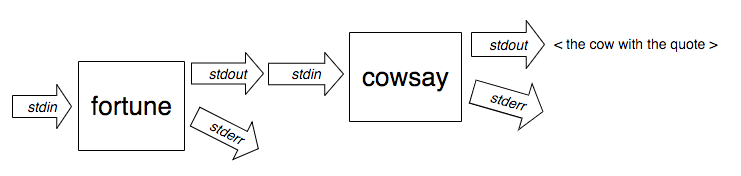
What would you have `cat file1 file2` do? Add newlines in between the files? It simply concatenates. It shouldn't even differentiate on the content. It's just arbitrary binary data to it. I can even use it on mp3s to join them. Why should it be limited to text files with newline separators? Add an option to add newlines in between the files? Why complicate matters? Simplicity is king! Let's do more with less software.
First of all, that's a hack zsh really shouldn't have to do. It's not like it can see the output of the commands that it runs. That's the job of the terminal. To make that '%' effect work, when a command it's waiting for dies, it outputs a '%' and then as many spaces as it knows there are columns in the terminal and then a carriage return '\r'. So it uses line-wrapping to move to the next line if there's content in the current one. That's really out of scope of what a shell should be doing. It also will not work if you're not working with the shell through a terminal, but something else like a tcp connection or a serial device. What's going to happen then is that that last "line" is going to disappear in zsh. The prompt will be rendered on top of it.
Anyway, it's not just about the shell prompt. Things are just simpler and more composable when using it as a terminator instead of a separator.
Consider programs that might every now and then have to warn you about errors, like this:
Now consider what would happen if you need to conditionalize the first line:
cmd() {
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-1" "$1"
fi
sleep 1
>&2 printf "\n%s-error-2" "$1"
}
Now, if that first line doesn't output anything, you'll get a extra, blank line. So, you need to include the newline in the conditional body:
cmd() {
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-1" "$1"
>&2 printf "\n"
fi
sleep 1
>&2 printf "%s-error-2" "$1"
}
Now what if you need to conditionalize the last line?
cmd() {
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-1" "$1"
>&2 printf "\n"
fi
sleep 1
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-2" "$1"
end
}
should the newline go in the first or second conditional body? If it's on the first, then if the first condition is true and the second is false you'll get a trailing newline (something you don't want if you're trying to have separators).
What's the solution here? The newline will have to be added only when BOTH conditional bodies run:
cmd() {
if (( $RANDOM % 2 == 0 )); then
first_was_true=1
>&2 printf "%s-error-1" "$1"
fi
sleep 1
if (( $RANDOM % 2 == 0 )); then
if [[ $first_was_true ]]; then
>&2 printf "\n"
fi
>&2 printf "%s-error-2" "$1"
end
}
What if you have a 3rd conditional error? Well, that's a new newline that will have to be output iff the second and third ran or the first and third ran:
cmd() {
if (( $RANDOM % 2 == 0 )); then
first_was_true=1
>&2 printf "%s-error-1" "$1"
fi
sleep 1
if (( $RANDOM % 2 == 0 )); then
second_was_true=1
if [[ $first_was_true ]]; then
>&2 printf "\n"
fi
>&2 printf "%s-error-2" "$1"
end
sleep 1
if (( $RANDOM % 2 == 0 )); then
if [[ $first_was_true || $second_was_true ]]; then
>&2 printf "\n"
fi
>&2 printf "%s-error-2" "$1"
end
}
Can you see how this quickly becomes unwieldy? Each new body becomes coupled to the ones before it. The third conditional needs to know about the first and second when semantically it shouldn't need to care at all! If you use line terminators, things are much simpler:
cmd() {
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-1\n" "$1"
fi
sleep 1
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-2\n" "$1"
fi
sleep 1
if (( $RANDOM % 2 == 0 )); then
>&2 printf "%s-error-3\n" "$1"
fi
}
This isn't just an arbitrary Unix decision. It's objectively good design.
When a job completes, it should end with a newline (if it printed anything). That's good UX. But you cannot mandate this for two big reasons:
* You can't enforce this at the process level, because you may want to use multiple process invocations to build up a single line of text, or want to accept input after printing a prompt. So this logic has to live at the job level.
* Programs that print data that exist somewhere else should not be adding unexpected newlines. `cat foo > bar` should produce an identical copy of foo, not a copy with a newline added.
Since this has to happen at the job level, the only place this can be done is in the shell. Ideally there'd be some way to coordinate with the terminal emulator to say "if I'm not at the beginning of the line already, please add some indication of this and move the cursor to a new line", which not only means the terminal is responsible for the indicator instead of the shell, but it also enables smart behavior like being able to copy the output without including the line terminator indicator
Unfortunately, terminal emulators don't have a way to do this, so the shell has to hack it together.
If it's "individual programs should use line terminators as convention and if the shell can help improve UX in the face of programs that break convention then it should", then I agree with you. What I meant by how zsh shouldn't be doing this is that if programs and people working on the command line followed the convention of terminating newlines, then the shell wouldn't need to do that.
If it's "individual programs should use line separators and the shell should add the terminating newline", then I disagree. I don't think shells and terminals are so fundamental that this behavior should depend on them. It also does nothing to address the example of `cmd foo | cmd bar` that I gave because that's 1 job.
It's, as I said, that programs should use line terminators, but we cannot mandate that all programs do use line terminators, so it's still the responsibility of the shell to deal with this. Specifically, it's a reaction to
> First of all, that's a hack zsh really shouldn't have to do.
In an ideal world, zsh wouldn't need a hack, but it would still need to send a signal to the terminal emulator to say "please ensure the cursor is at the beginning of a line; if it's not, mark this somehow so the user understands". Slightly less ideally, a simple way to say "am I at the beginning of a line?" (this is less ideal only in that now the terminal can't be smart about copying program output). But either way, it's still the responsibility of the shell to ensure its prompt ends up starting at column 0 without overwriting the previous program's output. Because no matter what conventions you establish, there will be programs that exit without printing a line terminator (even the best-behaved of programs can still do this if they use unbuffered output and you send a signal to kill the process in the middle of a line).
The idea that every line must end with a newline is a restriction caused by the fact that on Unix we just see everything as a stream of bytes. So what you say makes sense on Unix, where that's true, and the argument falls apart as soon as you leave those assumptions. That's why this is a Unix-ism, and that's why people on other platforms (or even people on Macs) don't care so much about files ending with line breaks.
In the modern day, we are required to put a line break at the end of text whether or not there is a line feed there. This is rule LB4 of UAX #14, which all Unicode-compliant line breaking algorithms must conform to. According to the Unicode specification, the line feed is a break between lines, not a line terminator, and this is fine. Not all the world has to act like Unix, and most of it doesn't.
The original idea behind streams is decidedly more Unix-like than the whole BSD sockets hack. Also it is only partially relevant to networking, conceptually it is generalization of the concept of line discipline, IIRC the original implementation of PTYs in SysV was layered on top of streams. Well, then there was X/Open and another standardization bodies who though that ISO OSI stack is a good thing (you have to be standards body to be capable of believing that) standardized STREAMS (note the capitalization) and build ISO OSI API in terms of that, complete with userspace layer in between that hides all the complexity in order for the thing to be actually usable.
This is interesting to compare to the 3270 terminals in mainframes. On those the terminal inherently understands labels and fields, and typing doesn't necessarily go to the host until you submit. It's closer to a web browser than a Unix style terminal.
When I was working on one open source terminal library, I wanted to get a 3270 family terminal (with appropriate bridge for TCP/IP or RS232), just to look for ideas that were lost to the Unix and other communities I already know.
I understand some other, more generic serial terminals, like were used on Unix, also had block modes (local editing of screen regions), but I'm not aware of Unix software taking advantage of that.
Recently I broke my terminal emulator's config while I didn't have an internet connection so I had to use a virtual terminal to fix it. It made me wonder, does anybody use virtual terminals as their daily drivers?
I did from about 6th-9th grade. I pretty much just used ttys except for the odd google doc I would need to use a laptop for. I would just use my rpi model a for everything.
tmux was pretty much required for any work. I would use irc, w3m for internet browsing, mutt for email, and vim for programming.
I thought if I only used the terminal I would become very good at it, kind of true but I have never had the ability to use linux at work yet. I learned a lot more by breaking and fixing X once I got a machine faster than an RPI model A.
I don't recommend doing this, it was not worth it.
As in most of the time the window focus is on a terminal? Yes.
In my computer, 90% of the time there are only 2 types of windows open. 1 is the web browser, and the other is the terminal. Sometimes I open up Emacs to read my mail or write some notes in org-mode, but my text editor of choice is vim in a terminal, not even gvim.
For a daily driver... it's hard to imagine the conditions where that would be better than using X. Maybe if one's stuck with a machine so old (like 90's old) where even light window managers lag, then maybe. You normally wouldn't install X on servers or raspberry-pi's or other purpose built machines like routers, but you also wouldn't use them as a daily driver. I imagine even people that need to work on those extensively would rather log-in via ssh from their real daily-driver.
I did for about six months, and then decided it was more trouble than the experiment had fun potential. I ran GNU screen, emacs with eww and every other special get-stuff-done mode, FBI, fbgs, and a few other tools like that, and while I got it working okay, it was never a pleasure to use.
I did, 14-13 years ago. I would just run mc/mcedit in VT and switch virtual terminals with Alt+F#. I did most of my programming there with mcedit, but switched to X for web browsing. I was writing distro build scripts and networking libraries in C, so I didn't need the browser that often.
I grew up on MS-DOS, so it was not really such a long stretch, to work this way.
I used to do that on laptops as a way to compensate for lack of an mouse. I dont do that anymore that much, because I mostly write things with web interfaces and because TrackPoint is actually better pointing device than mouse.
If you’re intersted in this, I recommend Emacs or tmux (as a multiplexer and/or your “everything” editor), netsurf (web browser with frame buffer display mode for graphical interaction), and fbi (framebuffer image viewer).
The article doesn't get into the few ways that terminals are more than normal stdio streams, but it turns out you can do a lot without knowing any of that. For one terminal library I made, I was able to avoid any extra native code in the process, using only unbuffered streams and a kludgey call out to `/bin/stty` to set raw input on that end. (Next time, I'd probably just do FFI to native code.) https://www.neilvandyke.org/racket/charterm/
Does an OS/terminal/shell exist that allows one to apply a different interpretation to streams than as a stream of characters? For example JSON objects, or even images?
Not sure how useful it would be, but it could look like this:
$ cat car.png | grep "traffic-light"
Illegal operation: stream is of type image
$ cat car.png
(image appears)
Unfortunately it comes with risks. With byte streams you can have an arbitrary max buffer size after which the program has to wait to write. With objects you can run out of memory trying to pass everything in a single object. I hit this trying to generate large CSVs in powershell.
Recently I needed to multiplex stdin to both stdout and stderr and was surprised that none of the coreutils tools supported that. The closest is `tee /dev/stderr` which only works on system where stderr is bound to that virtual device. It seems such a basic thing to do when you want to debug a pipe.
This is a great article and very beginner friendly as well. While I didn't learn anything new from this, it helped me organize the concepts in a way that would be much easier to communicate with someone else.
Thanks for posting. I bookmarked this incase I ever need to explain streams to someone.
> So `cat /tmp/hello.txt` does not read stdin from `/tmp/hello.txt`? Why does `cat /tmp/hello.txt` set stdout to `/tmp/hello.txt` this is confusing
While stdin, out and err are files, they're not really the same thing as a /tmp/hello.txt type file you're thinking of. They're file system objects with special permissions. And while the idea is you'd use normal file read / writing APIs on them they're really more like FIFO buckets (technically it's a symlink to a file - for reasons that will make more sense shortly)
Take the example:
cat /tmp/hello.txt | grep world
(ignoring for the moment the "abuse of cat" for the sake of this example)
So what would happen there `cat` would write to this bucket (the location of it varies from one OS to another) and another process in the pipe (eg `grep`) would read from that same bucket. But from the perspective of `cat` it's STDOUT and from the perspective of `grep` it's STDIN - even though they're the same file.
Things get a little more complicated when you start talking about redirection but essentially because each programs STDIN, STDOUT and STDERR file is actually just a symlink, when a program starts it's symlink points to another file instead of the normal one that would be next (or previous) in the pipeline. However this is all done automatically by the OS when you make the syscalls.
Things get even more complicated when you start talking about stuff that is read from or written to your terminal because they will be slightly different file system objects again but with a bit set to identify them as a pseudo-TTY. It's not really worth getting into the mechanics of it here. However ostensibly the principle is the same as the above.
I see, and thank you for the clarification. My main problem then is the blog post for the redirection section is poorly written and plain wrong with regards to the examples and pictures.
Their example is
$ cat /tmp/root_content.txt
And then in the picture the show that the `cat` program's stdout is `/tmp/root_content.txt`, which is incorrect according to your description. This would only be correct if it was then redirected or piped.
Their description was correct. What they missed off the /tmp/root_content.txt example was that the shell would create that file first, then launch the program pointing it's STDOUT to that file.
Because those streams are file system objects that use the same reading and writing APIs as regular files, it means you can also substitute them for regular files too. Which is what's happening in that specific example.
Essentially UNIX supports a whole array of special files that might behave slightly differently in the background but all can be interfaced with using the same principles as any regular file. It's quite a clever solution - albeit not without it's problems, kludges and mistakes too.
There are too many mistakes and typos in this to recommend it. Better if you go straight to the end and click on "TTY demystified" and the other links he recommends.
The idea is not to be driven by simplicity per se, but by composability. Build software wherein you take it for granted that it will be used in many contexts, and that it is only ever able to solve 'part' of the problem because other parts may not yet be understood.
If you're not focussed on building simple systems, then you're unlikely to be able to compose them, and if you can't compose them, they will likely become obsolete quickly. So the goal is really to avoid having to implement the same things over and over again.
Yes sorry, I totally agree with this and I am digressing. I'm reacting to the first words of the article:
> I always try to build less software. Less software means you have to spend less time updating it, less time fixing it, and less time thinking about it. The only thing better than “less software” is no software at all.
The problem is that I have been harassed on this very basis (i.e. that of a philosophically stated point of view) by people that are less able than me and this lead to writing over and over again the same dumb code for 15,000 lines while it could have been kept under 1000 (in fact I did it) (and as you may have already guessed it, this is resentment speaking here).
Actually you don't make things simpler, either you move complexity around, often concentrating it somewhere to alleviate its weight on other parts of the system, and they can then be described in shorter terms, enhancing the pace at which you can tweak them – or you get rid of that complexity, moving it out of the code, i.e. delegating it to future implementations or to manual maintenance support tasks.
This is the bit that is problematic to me:
> [you have to spend] less time thinking about it
Absolutely not. In some parts yes, definitively, but some other parts will be incredibly dense, and will require a very slow reading pace. When you want to change such code, you have to sit in front of your screen, thinking hard about what happens for 30 minutes, and when you get it it's a 5 lines change.
Maybe the author doesn't consider this in this article because he doesn't have to deal with implementing these piping heuristics, he already has those of bash.
Now why am I pulling the cow's horn like this ? Because this also encourages people into simpler thinking and they mix this up with whatever noble ideal simplicity actually refers to, while, as Hickey pointed out, it's a lot more about the tradeoff that populate the quadruality between easy/simple vs complex/complicated. Nonetheless, here they come, shitting on my tree-traversal – not a simple thing, not in their realm, and here they are, "flattening" it in a 200 files long pull request.
As for how software should be done, err ... I think I never heard what I'd say, i.e. that software should be developed by programmers or in other words teammates, not pupils nor slaves, and that these people, as thinking beings, shouldn't be treated as things that conform and must be, quite to the contrary, they should let be.
What an attention grabbing first line but ultimately contradictory. If you hate software you hate streams because streams are software.
Guess what? I hate computers. If you do less streaming across computers and put everything in a monolithic code base you need less computers. Is what I just said pointless, obvious and attention grabby? well so is the first couple lines of this article.
{kind=link}